RAGLight
综合介绍
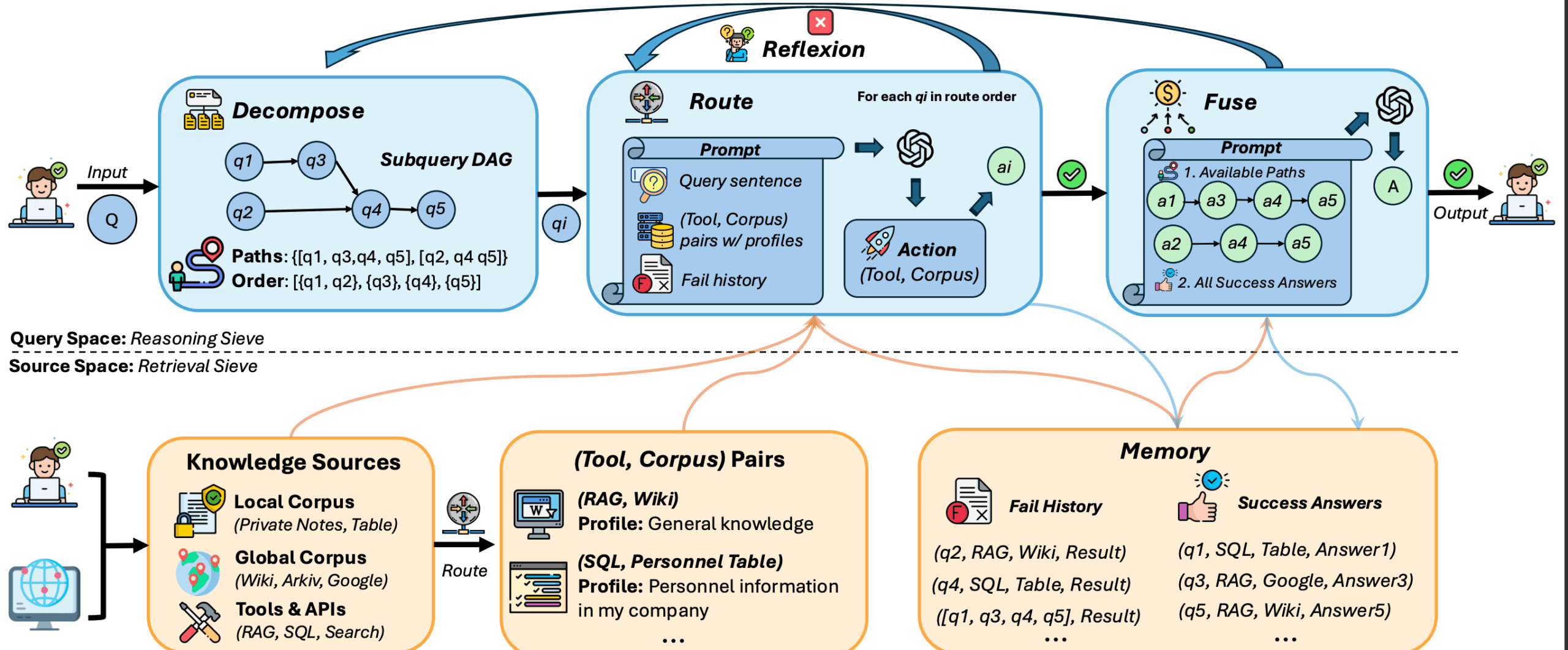
RAGLight是一个轻量级、模块化的Python库,它主要用来实现检索增强生成(RAG)功能。这个工具的核心作用是让大语言模型(LLM)在回答问题或生成内容时,能够先从用户指定的文档中检索相关信息,然后再结合这些信息给出更准确、更具上下文的回答。它的设计兼顾了简洁性和灵活性,提供了许多可以自由组合的模块化组件。用户可以轻松地集成不同的大语言模型、嵌入模型和向量数据库。对于希望构建能理解特定知识背景的AI应用,比如根据内部文档回答问题的客服机器人,或者个人知识库的问答助手,RAGLight提供了一个理想的解决方案。它不仅支持传统的RAG流程,还引入了代理(Agentic RAG)和思维链(RAT)等更高级的模式,以提升问答的准确性和逻辑性。
功能列表
- 命令行向导: 提供一个交互式的命令行工具
raglight chat,可以引导用户完成文档选择、模型配置和聊天会话的全过程,无需编写代码。 - 多种模型支持: 可以无缝集成多种大语言模型(LLM)服务,包括Ollama、LMStudio、vLLM、OpenAI API和Mistral API。
- 灵活的嵌入模型: 支持接入HuggingFace、Ollama、vLLM和OpenAI等多种来源的文本嵌入模型,用于将文档向量化。
- 多种流程模式: 内置三种核心工作流程:
- RAG: 标准的检索增强生成流程,先检索后生成。
- Agentic RAG: 使用一个代理(Agent)来更智能地从未经组织的非结构化数据中检索信息。
- RAT (Retrieval Augmented Thinking): 在检索和生成之间增加了一个“推理”步骤,让模型能进行更复杂的思考和反思。
- 支持多种文档源: 能够读取并索引多种格式的本地文档,如PDF、TXT、DOCX,以及Python和JavaScript等代码文件。同时支持直接从GitHub仓库抓取代码和文档作为知识源。
- 可扩展架构: 用户可以根据自己的需求,通过简单的配置或代码,轻松替换向量数据库(目前支持Chroma)、嵌入模型或大语言模型。
- Docker支持: 项目提供了Dockerfile示例,方便用户在容器化环境中部署和运行。
使用帮助
RAGLight的设计目标是让开发者和普通用户都能快速上手。下面将详细介绍它的安装和使用方法。
环境准备
在使用RAGLight之前,你需要先在本地环境安装并运行一个大语言模型服务。RAGLight本身不提供模型,它是一个连接你的文档和模型的“桥梁”。最常用的本地模型服务是Ollama。
- 安装Ollama:
- 访问Ollama官方网站(ollama.com),根据你的操作系统(macOS, Linux, Windows)下载并安装。.
- 下载模型:
- 安装完成后,在终端运行命令来下载一个你需要的模型。例如,下载Llama 3模型:
ollama run llama3- 该命令会自动下载并启动模型。当看到 ">>> Send a message (/? for help)" 提示时,说明模型已准备就绪。
安装RAGLight
你可以通过Python的包管理器pip直接安装RAGLight库。
pip install raglight
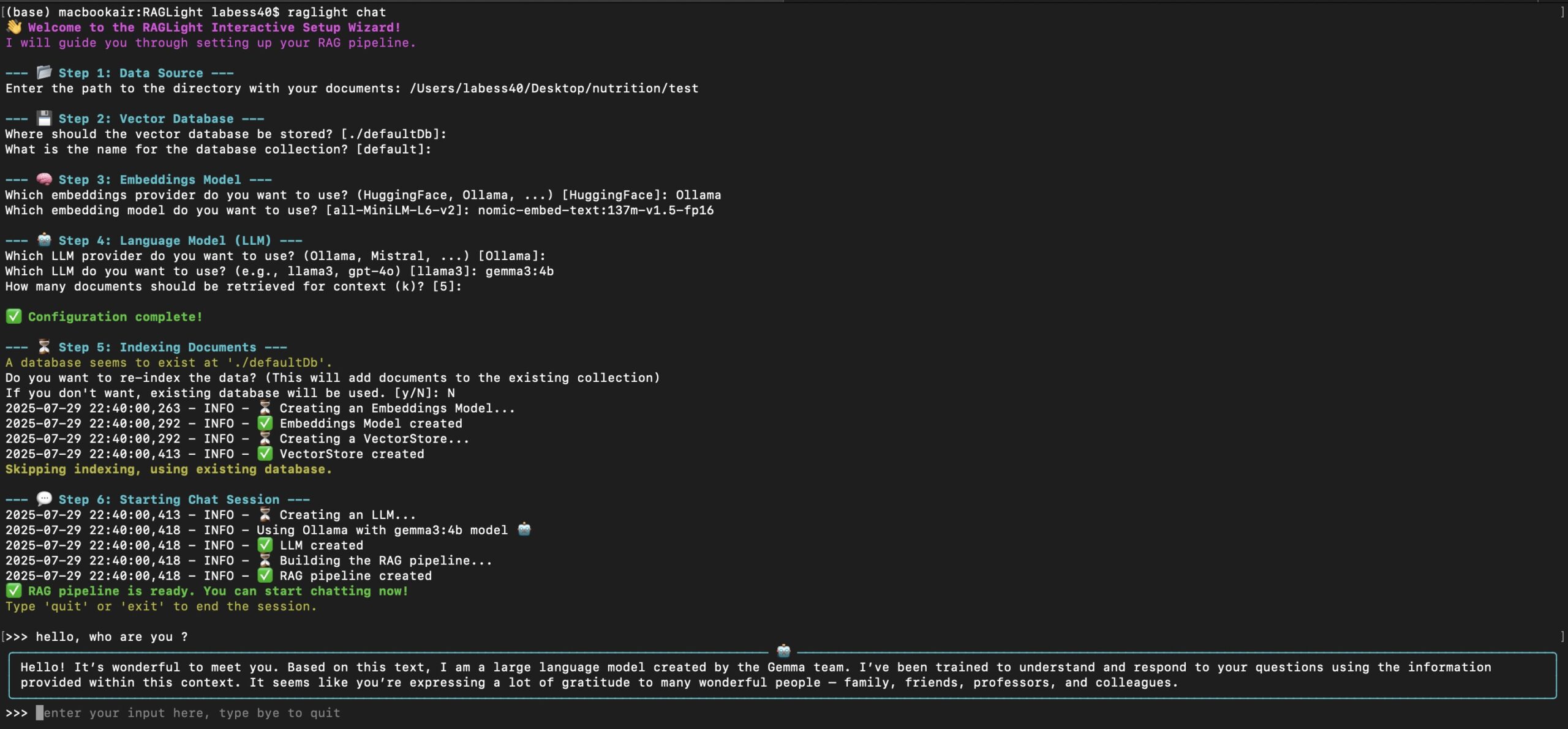
方法一:使用命令行向导(最简单)
这是为非程序员用户或希望快速验证效果的用户准备的功能。它通过一个问答式的向导,让你无需写一行代码就能和自己的文档聊天。
- 启动向导:打开你的终端,直接输入以下命令:
raglight chat - 跟随向导配置:程序会依次询问你几个问题,引导你完成设置:
- 选择文档路径: 它会要求你输入存放文档的文件夹路径。
- 设置向量数据库: 你需要为即将建立的知识库指定一个存储位置和名称。
- 选择嵌入模型: 向导会列出可用的嵌入模型(通常默认即可),用于分析和索引你的文档。
- 选择大语言模型: 向导会检测你本地正在运行的LLM服务(如Ollama中的
llama3),并让你选择使用哪个模型进行对话。
- 开始聊天:配置完成后,RAGLight会自动处理你的文档(读取、分割、向量化并存入数据库)。这个过程可能需要一些时间,具体取决于文档数量和大小。处理完毕后,你就可以在终端里直接输入问题,与你的专属知识库进行对话了。
方法二:使用Python库(更灵活)
对于开发者来说,直接在Python代码中使用RAGLight库可以实现更复杂和定制化的功能。
1. 准备工作
首先,创建一个项目文件夹,并准备一个用于存放环境变量的.env文件。
- 创建
.env文件:在你的项目根目录创建一个名为.env的文件。如果你需要使用像Mistral或OpenAI这样需要API密钥的服务,可以在这里配置它们。MISTRAL_API_KEY="你的Mistral API密钥" OPENAI_API_KEY="你的OpenAI API密钥"
2. 基础RAG流程实现
下面是一个完整的Python代码示例,展示了如何搭建一个基础的RAG问答流程。
- 准备文档:在你的项目下创建一个名为
knowledge_base的文件夹,并将你想要查询的PDF、TXT等文件放进去。 - 编写Python脚本:创建一个Python文件(例如
app.py),并写入以下代码:from raglight.rag.simple_rag_api import RAGPipeline from raglight.models.data_source_model import FolderSource from raglight.config.settings import Settings from raglight.config.rag_config import RAGConfig from raglight.config.vector_store_config import VectorStoreConfig # 1. 设置知识源:指定包含你文档的文件夹 knowledge_base = [ FolderSource(path="./knowledge_base") ] # 2. 配置向量数据库 # 这里我们使用默认的HuggingFace嵌入模型和Chroma数据库 vector_store_config = VectorStoreConfig( embedding_model=Settings.DEFAULT_EMBEDDINGS_MODEL, provider=Settings.HUGGINGFACE, database=Settings.CHROMA, persist_directory='./db', # 指定数据库存储在本地的'db'文件夹 collection_name="my_docs" ) # 3. 配置RAG核心参数 # 指定使用Ollama服务和你下载好的模型(如llama3) config = RAGConfig( llm="llama3", provider=Settings.OLLAMA, knowledge_base=knowledge_base ) # 4. 初始化并构建管道 # RAGPipeline会将上面的配置组合起来 pipeline = RAGPipeline(config, vector_store_config) # 首次运行时,需要构建知识库。这会读取、处理并索引所有文档。 # 如果数据库已存在,它会直接加载,不会重复构建。 print("正在构建或加载知识库...") pipeline.build() print("知识库准备就য়াম.") # 5. 开始提问 print("现在可以开始提问了 (输入 'exit' 退出):") while True: question = input("> ") if question.lower() == 'exit': break # 调用generate方法,传入你的问题 response = pipeline.generate(question) # 打印模型的回答 print("\nAI回答: ", response, "\n") - 运行脚本:在终端中运行你的Python文件:
python app.py程序会首先构建知识库,然后你就可以在终端中输入问题进行查询了。
应用场景
- 个人知识库问答用户可以将自己收集的各种资料,如PDF电子书、Markdown笔记、代码片段等放入一个文件夹。通过RAGLight,可以搭建一个私人的问答机器人。当需要查找特定信息时,无需手动翻阅文件,直接向机器人提问即可获得答案。
- 企业内部智能客服企业可以将其产品手册、帮助文档、FAQ列表等作为知识源。利用RAGLight构建一个内部客服系统,员工在遇到问题时,可以快速从该系统中获得标准化的、准确的解答,提升工作效率。
- 代码辅助开发开发者可以将一个或多个GitHub代码仓库作为知识源。当需要理解项目架构、查找特定函数实现或学习API用法时,可以直接向RAGLight提问。例如:“请解释一下
RAGPipeline类的初始化过程” 或 “如何在项目中实现自定义的数据加载器?” - 学习与研究学生或研究人员可以将某个领域的学术论文、研究报告、网络文章等资料整理起来,构建一个专题知识库。在撰写论文或进行研究时,可以利用RAGLight快速查询和整合信息,辅助思考和写作。
QA
- RAGLight支持哪些类型的语言模型?RAGLight设计上是模型无关的,目前已内置支持通过Ollama和LMStudio运行的本地模型,以及通过API调用的OpenAI模型和Mistral模型。用户也可以通过配置vLLM服务器来使用兼容的模型。
- 我需要自己准备向量数据库吗?不需要。RAGLight默认使用
Chroma作为向量数据库,它是一个轻量级的嵌入式数据库。在首次运行时,RAGLight会自动在指定的目录(如./db)下创建和管理数据库文件,无需用户手动安装或配置。 - 处理大量文档时速度很慢怎么办?文档处理(尤其是嵌入生成)是一个计算密集型过程,速度取决于你的CPU/GPU性能和文档数量。这个过程通常只需要在首次创建知识库或更新文档时执行一次。一旦知识库构建完成,后续的查询(检索)速度会非常快。
- Agentic RAG 和普通的 RAG 有什么区别?普通的RAG流程是线性的:提问 -> 检索相关文档 -> 生成答案。而Agentic RAG引入了一个“代理”(Agent)角色。这个代理可以根据初始问题进行思考,并主动决定是否需要以及如何从知识库中检索信息,甚至可以进行多轮检索来完善上下文,从而处理更复杂或模糊的查询。
- 是否可以把多个GitHub仓库作为知识来源?可以。在配置知识源(
knowledge_base)时,你可以传入一个包含多个GitHubSource对象的列表,每个对象指向一个不同的代码仓库。RAGLight会依次克隆并索引所有这些仓库的内容。